
We present a framework for perspective-aware reasoning in vision-language models (VLMs) through mental imagery simulation. Perspective-taking—the ability to perceive an environment or situation from an alternative viewpoint—is a key benchmark for human-level visual understanding, essential for environmental interaction and collaboration with autonomous agents. Despite advancements in spatial reasoning within VLMs, recent research has shown that modern VLMs significantly lack perspective-aware reasoning capabilities and exhibit a strong bias toward egocentric interpretations. To bridge the gap between VLMs and human perception, we focus on the role of mental imagery, where humans perceive the world through abstracted representations that facilitate perspective shifts. Motivated by this, we propose a framework for perspective-aware reasoning, named Abstract Perspective Change (APC), that effectively leverages vision foundation models, such as object detection, segmentation, and orientation estimation, to construct scene abstractions and enable perspective transformations. Our experiments on synthetic and real-image benchmarks, compared with various VLMs, demonstrate significant improvements in perspective-aware reasoning with our framework, further outperforming fine-tuned spatial reasoning models and novel-view-synthesis-based approaches.

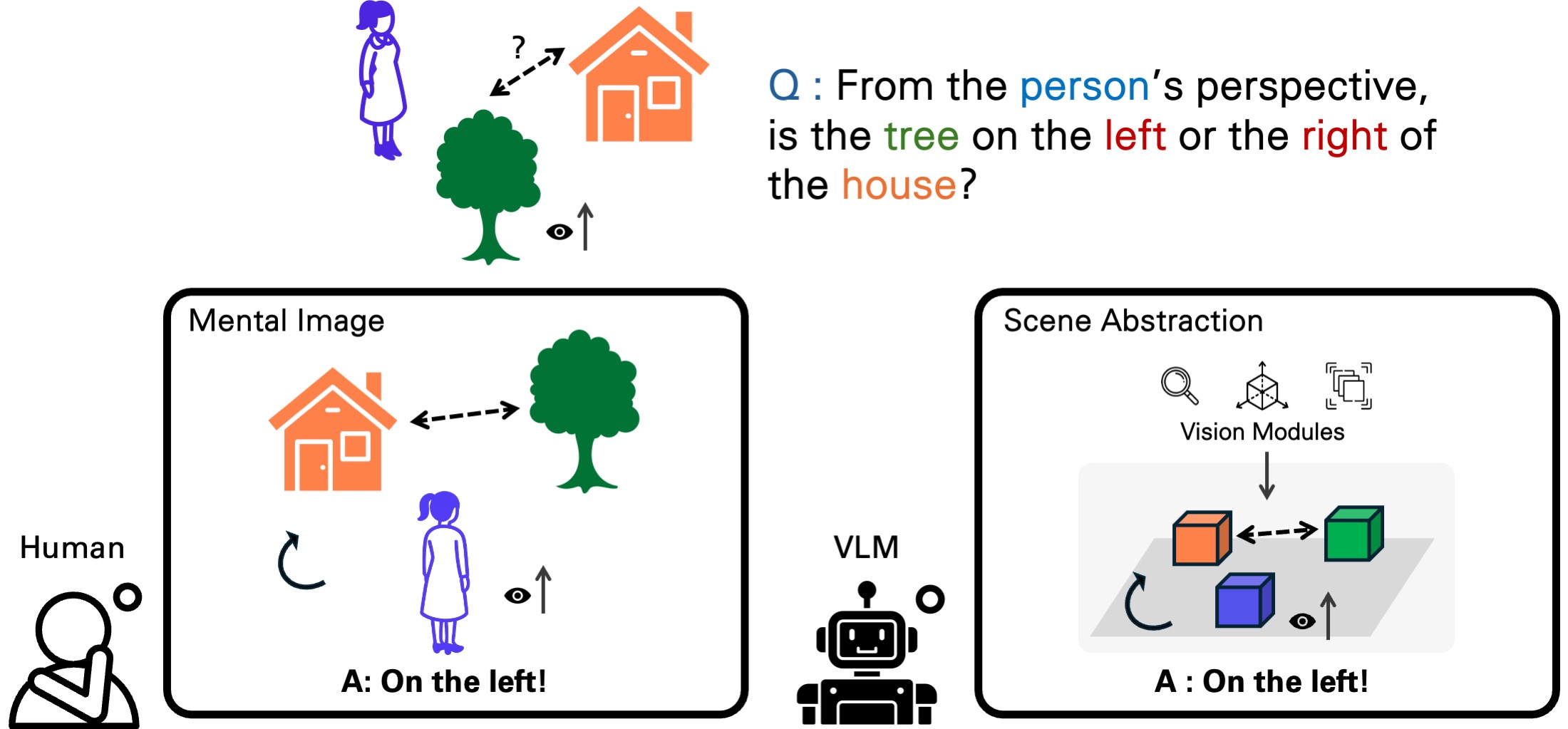
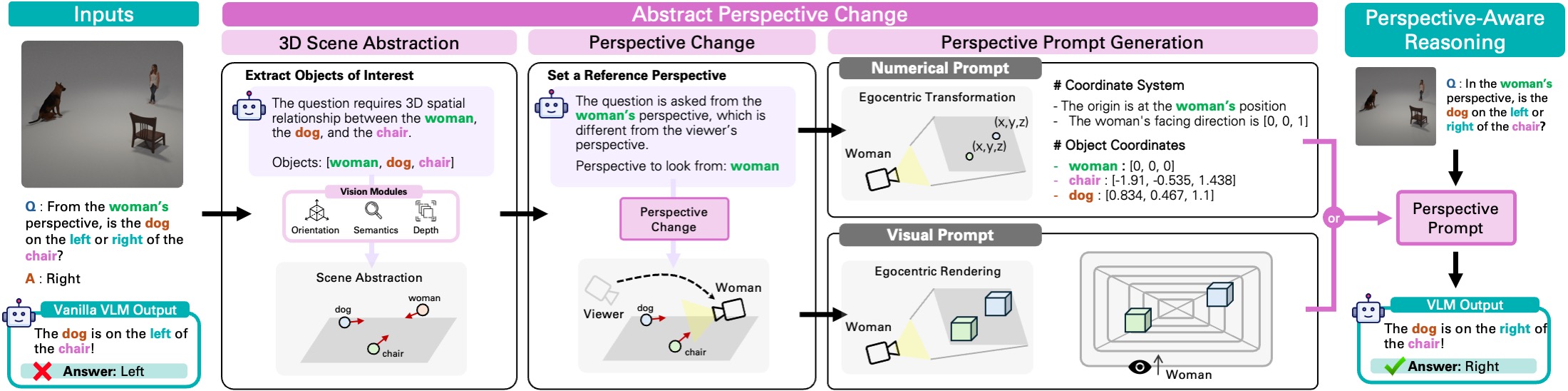
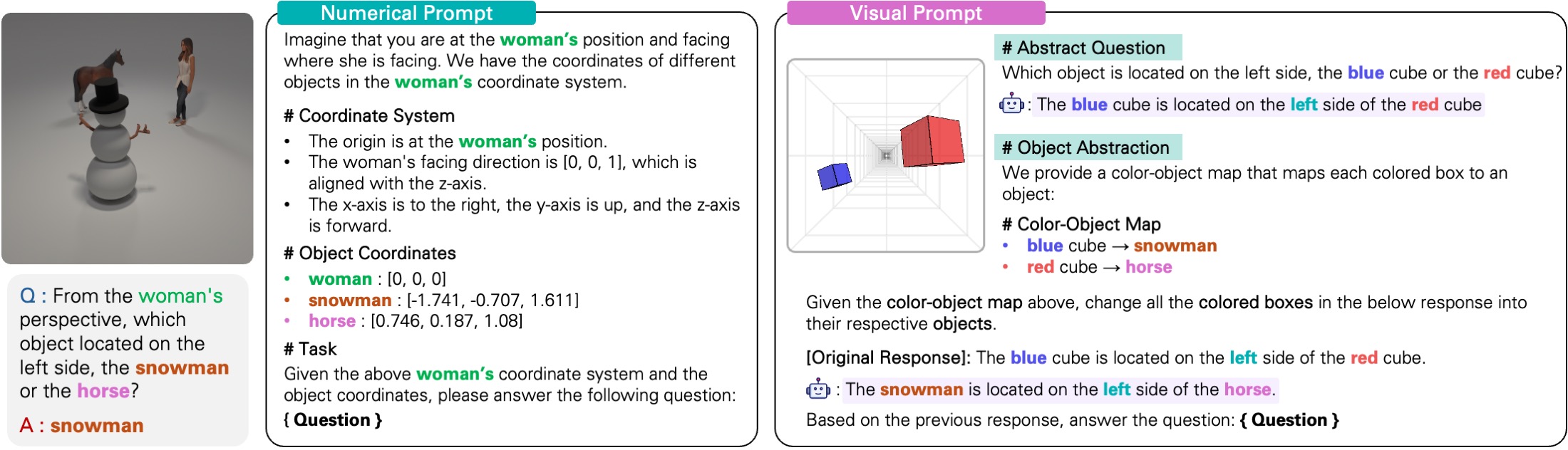

Spatial Reasoning with Perspective Change. Recent VLMs such as Qwen2.5-VL [10] and Cambrian-1 [11] often struggle with spatial reasoning tasks that require a shift to a specific reference viewpoint. In constrast, our APC effectively handles such perspective changes by constructing a scene abstraction and delivering the transformed view through a simple prompting technique.
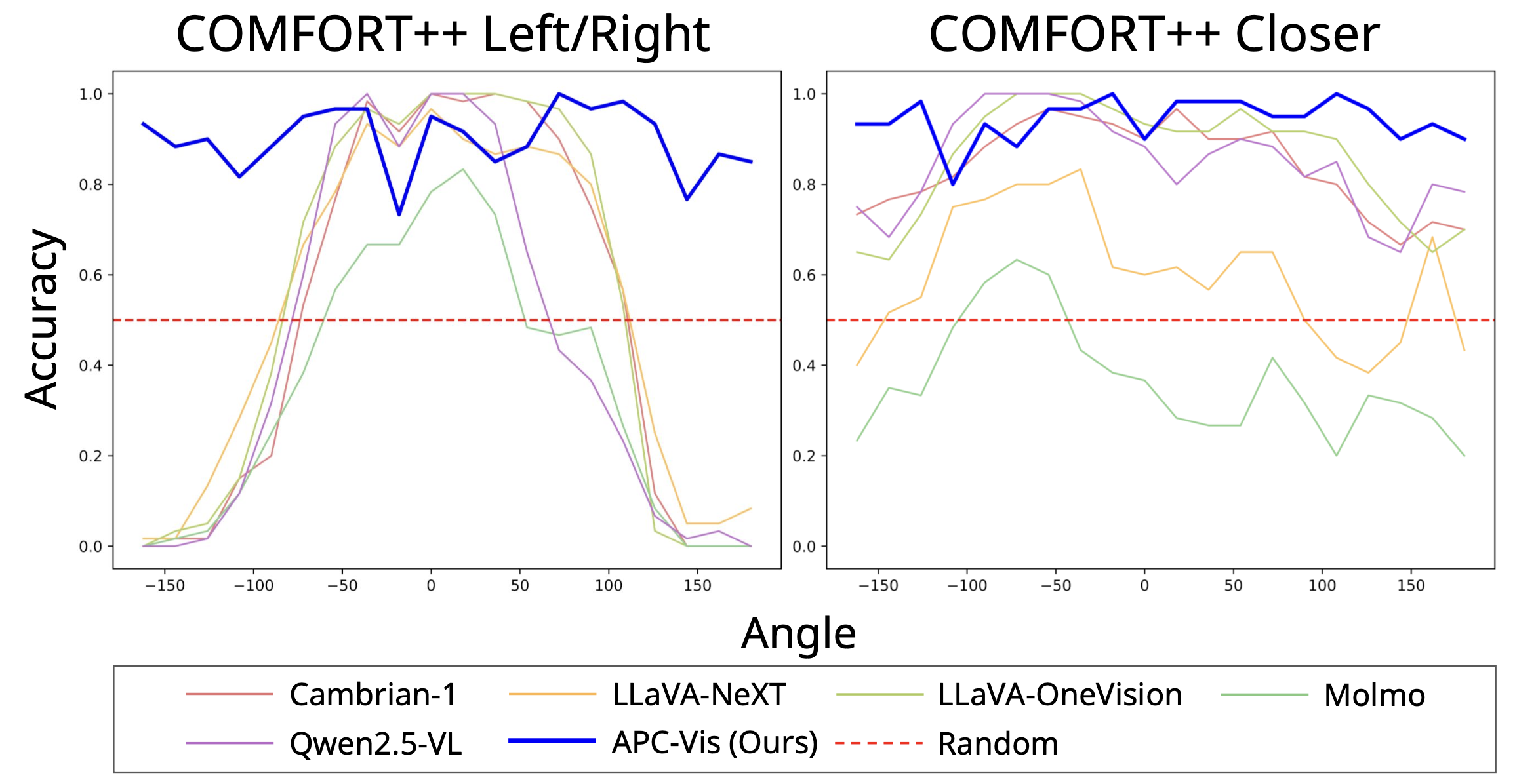
Perspective Awareness. Each plot shows accuracy versus the angular offset θ between the camera and the reference viewpoint. While baselines show clear degradation at certain ranges of θ, APC retains robust accuracy across all angles, demonstrating strong perspective-aware reasoning.
If you find our work helpful, please cite the following paper.
@inproceedings{lee2025perspective,
title = {Perspective-Aware Reasoning in Vision-Language Models via Mental Imagery Simulation},
author = {Lee, Phillip Y. and Je, Jihyeon and Park, Chanho and Uy, Mikaela Angelina and Guibas, Leonidas and Sung, Minhyuk},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision},
year = {2025}
}